
Working with Text on Apple Devices: Key Natural Language Tricks You Can Use
Some Approaches That Have Helped in Real Projects

Building smarter apps is something many of us are aiming for.
Apple’s Natural Language framework gives us a surprisingly broad set of tools—right on-device—but real-world usage often raises more questions than official docs answer.
This guide collects five NLP techniques you might find useful, with code samples, practical scenarios, and the sorts of caveats I wish someone had mentioned early on.
1. Language Identification with NLLanguageRecognizer
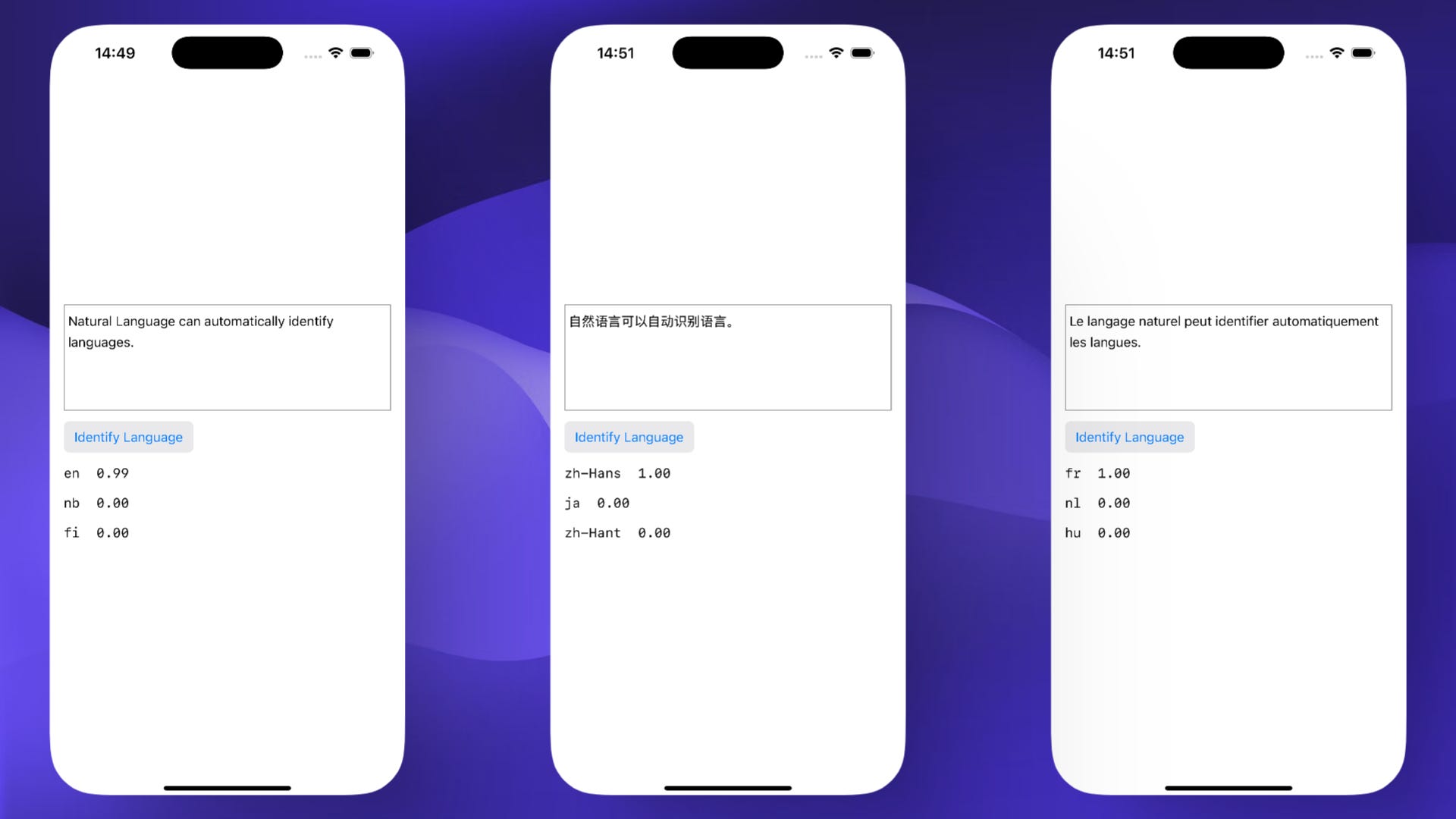
What it does:
Tries to figure out what language a piece of text is in.
When this helps:
Automatically choosing localization, keyboard, or spellcheck
Validating or tagging user-generated content in a multilingual app
Flagging unexpected input for further review
Code sample:
import SwiftUI
import NaturalLanguage
struct LanguageIdentifyView: View {
@State private var text = "Natural Language can automatically identify languages."
var body: some View {
VStack(alignment: .leading, spacing: 12) {
TextEditor(text: $text).frame(height: 120).border(.secondary)
Button("Identify Language") { }
.buttonStyle(.bordered)
ForEach(topLanguages(for: text), id: \.0) { code, prob in
Text("\(code) \(String(format: "%.2f", prob))").monospaced()
}
}
.padding()
}
private func topLanguages(for text: String) -> [(String, Double)] {
let recognizer = NLLanguageRecognizer()
// If your app expects certain languages more often, try languageHints.
// recognizer.languageHints = [.english: 0.8, .chinese: 0.2]
recognizer.processString(text)
let hyps = recognizer.languageHypotheses(withMaximum: 3)
return hyps.map { ($0.key.rawValue, $0.value) }
.sorted { $0.1 > $1.1 }
}
}
A few observations:
Works best with longer sentences. For very short or ambiguous input, results may be less certain.
If you see low confidence scores, consider asking users to clarify.
Adding languageHints can improve accuracy when you have a good guess about the user’s likely language.
2. Robust Tokenization with NLTokenizer
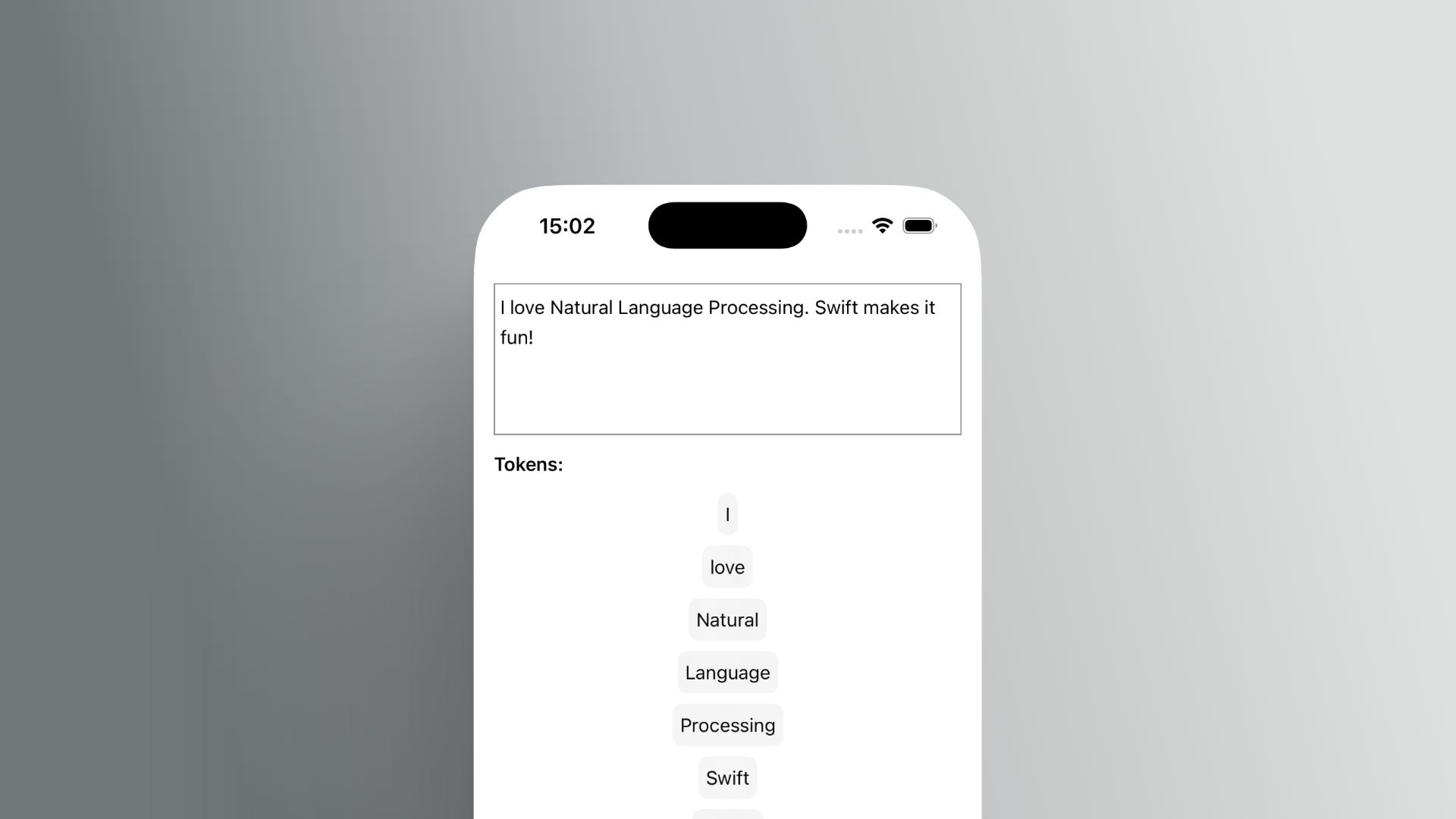
What it does:
Breaks up text into words, sentences, or paragraphs—in a way that works even for languages without spaces, like Chinese or Japanese.
Typical use cases:
Counting words or sentences
Highlighting, search, or text selection
Handling user input that mixes multiple languages
Code sample:
import SwiftUI
import NaturalLanguage
struct TokenizeView: View {
@State private var text = "I love Natural Language Processing. Swift makes it fun!"
var body: some View {
VStack(alignment: .leading, spacing: 12) {
TextEditor(text: $text).frame(height: 120).border(.secondary)
Text("Tokens:").bold()
ScrollView {
LazyVStack{
ForEach(tokens(in: text), id: \.self) { token in
Text(token).padding(6).background(.thinMaterial).cornerRadius(8)
}
}
}
}
.padding()
}
private func tokens(in text: String) -> [String] {
let tokenizer = NLTokenizer(unit: .word)
tokenizer.string = text
// tokenizer.setLanguage(.simplifiedChinese) // For better accuracy in CJK languages
var result: [String] = []
tokenizer.enumerateTokens(in: text.startIndex..<text.endIndex) { range, _ in
result.append(String(text[range]))
return true
}
return result
}
}Worth noting:
.word, .sentence, .paragraph, and .document are all supported units.
Works out-of-the-box for most languages, but setting the tokenizer language can sometimes help.
You don’t need to worry about weird edge cases like emoji—NLTokenizer handles most of those for you.
Heads-up:
If you’re coming from regular expressions or simple .split calls, the improvement in languages like Chinese is huge. Still, results aren’t always perfect—if your app depends on “perfect” tokenization, you might want to test with real user data.
Keep reading with a 7-day free trial
Subscribe to Just Do Swift to keep reading this post and get 7 days of free access to the full post archives.